数据分片
数据分片是应对海量数据存储与计算的有效手段。Pisanix 基于底层数据库提供了数据分片的治理能力,用户可以通过 Pisanix 水平扩展计算和存储。
数据分片介绍
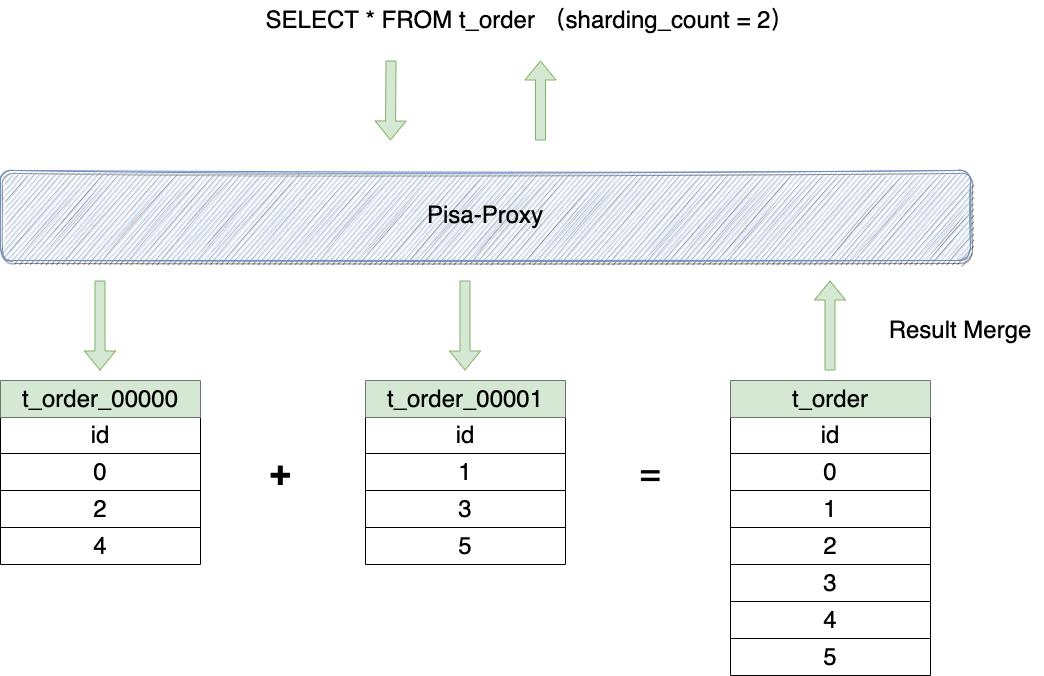
如下图,在数据分片中主要包函了 SQL 解析、SQL 改写、SQL 路由、结果归并这几个重要模块,
+------------+ +-------------+ +-----------+ +--------------+
| SQL Parse | --> | SQL Rewrite | --> | SQL Route | --> | Result Merge |
+------------+ +-------------+ +-----------+ +--------------+
名词解释
SQL 解析: 在分片中,请求到达 Pisa-Proxy 后会首先经过 SQL Parser,将 SQL 解析成 AST。
SQL 改写: 解析结束后,Pisa-Proxy 会根据分片规则对当前 SQL 语句进行改写,生成真实要执行的 SQL 语句。
SQL 路由: Pisa-Proxy 会根据分片规则,将改写好的 SQL 语句路由到后端对应数据源上执行 SQL 语句。
结果归并: SQL 被下推执行之后,Pisa-Proxy 会对查询结果进行归并,并最终返回给客户端。
SQL 改写介绍
在数据分片中,SQL 改写是很重要的一个模块。Pisa-Proxy 需要根据分片规则将 SQL 语句改写成真正要执行的 SQL 语句。在 SQL 改写中通常有以下几种改写类型。
1. 标识符改写
在 SQL 改写中,需要改写的标识符包括表名称、索引名称以及Schema名称。
表名称改写是指将找到逻辑表在原始SQL中的位置,并将其改写为真实表的过程。表名称改写是一个典型的需要对SQL进行解析的场景。 从一个最简单的例子开始,若逻辑SQL为:
SELECT order_id FROM order.t_order WHERE order_id = 1;
假设该表配置的分片键位 order_id 并且 order_id = 1,分片数指定为4,那么经过改写后的 SQL 语句为:
SELECT order_id FROM order.t_order_00001 WHERE order_id = 1;
下图展示了数据查询过程
以数据插入为例,数据写入过程如下图:
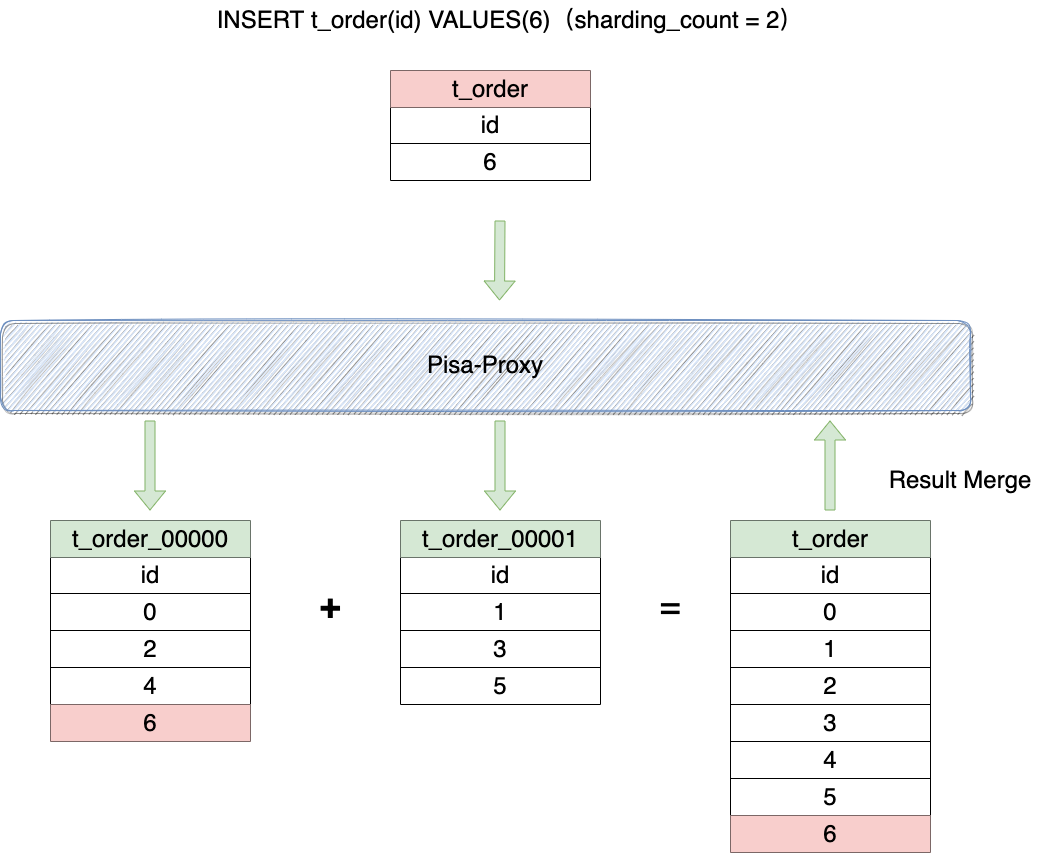
特别说明: SQL rewrite 在修改标识符计算实际表名时会自动根据分片规则添加表索引,索引规则位 表名_索引,索引位为5位表示。例如:t_order 表改写后为 t_order_00000。因此用户需要根据实际业务场景先创建好对应的表名
2. 补列
需要在查询语句中补列通常由两种情况导致。 第一种情况是 Pisa-Proxy 需要在结果归并时获取相应数据,但该数据并未能通过查询的SQL返回。 这种情况主要是针对 GROUP BY 和 ORDER BY。结果归并时,需要根据 GROUP BY 和 ORDER BY 的字段项进行分组和排序,但如果原始SQL的选择项中若并未包含分组项或排序项,则需要对原始SQL进行改写。 例如有以下 SQL 语句:
SELECT order_id, user_id FROM t_order ORDER BY user_id;
由于排序时用到了 user_id , 在结果归并时需要用到 user_id 这一列的数据,上面的 SQL 语句中包含了 user_id 的数据,因此不需要补列,只需要修改标识符即可。
SELECT order_id FROM t_order ORDER BY user_id;
这条 SQL 中依赖排序依赖于 user_id 因此需要补列,改写后的 SQL 如下:
SELECT order_id, user_id AS USER_ID_ORDER_BY_DERIVED_00000 FROM t_order_00000 ORDER BY user_id;
补列的另一种情况是使用AVG聚合函数。在分布式的场景中,使用avg1 + avg2 + avg3 / 3计算平均值并不正确,需要改写为 (sum1 + sum2 + sum3) / (count1 + count2 + count3)。 这就需要将包含AVG的SQL改写为SUM和COUNT,并在结果归并时重新计算平均值。例如以下SQL:
SELECT AVG(price) FROM t_order WHERE user_id = 1;
改写后的 SQL 如下:
SELECT COUNT(price) AS AVG_DERIVED_COUNT_00000, SUM(price) AS AVG_DERIVED_SUM_00000 FROM t_order_00000 WHERE user_id = 1;
支持特性
特性
- 基于单 shard-key 的静态分片规则
- 分片算法:crc32mod 和 mod
- 单库水平分表
- 分库
- 基于分片的查询,更新,删除,修改
使用限制
- 不支持子查询
- 不支持分库
- 不支持分布式事务
- 不支持基于表达式配置的分片规则
- 不支持跨库 join 查询
配置说明
| 属性 | CRD 字段 | 值类型 | 是否依赖 | 默认值 | 含义 |
|---|---|---|---|---|---|
| table_name | rules.tableName | String | 是 | 无 | 分片表名 |
| actual_datanodes | rules.actualDatanodes.valueSource.nodes.value | array[String] | 是 | 无 | 后端数据源 |
| binding_tables | N/A | arrayString] | 否 | 无 | 暂不支持 |
| broadcast_tables | N/A | array[String] | 否 | 无 | 暂不支持 |
| table_sharding_algorithm_name | rules.tableStrategy.tableShardingAlgorithmName | enum | 是 | 无 | 分片算法 |
| table_sharding_column | rules.tableStrategy.tableShardingColumn | String | 是 | 无 | 分片键 |
| sharding_count | rules.tableStrategy.shardingCount | u64 | 是 | 无 | 分片数 |
| database_sharding_algorithm_name | rules.databaseStrategy.databaseShardingAlgorithmName | enum | 是 | 无 | 分片算法 |
| database_sharding_column | rules.databaseStrategy.databaseShardingColumn | String | 是 | 无 | 分片键 |
CRD 配置示例
- 单库分表场景
apiVersion: core.database-mesh.io/v1alpha1
kind: DataShard
metadata:
name: catalogue
namespace: demotest
labels:
source: catalogue
spec:
rules:
- tableName: "t_order"
tableStrategy:
tableShardingAlgorithmName: "mod"
tableShardingColumn: "id"
shardingCount: 4
actualDatanodes:
valueSource:
nodes:
- value: "ds001"
- 分库场景
apiVersion: core.database-mesh.io/v1alpha1
kind: DataShard
metadata:
name: catalogue
namespace: demotest
labels:
source: catalogue
spec:
rules:
- tableName: "t_order"
databaseStrategy:
databaseShardingAlgorithmName: "mod"
databaseShardingColumn: "id"
actualDatanodes:
valueSource:
nodes:
- value: "ds001"